If you have ever tried to troubleshoot connecting EMR to a persistent remote metastore, you know it can be challenging. Here are the steps I've taking to test changes.
1. SSH into the master node of the cluster
2. sudo cp /usr/lib/hive/conf/hive-site.xml /usr/lib/hive/conf/hive-site.xml.old
2. sudo vi /usr/lib/hive/conf/hive-site.xml
3. Make changes as needed
4. ps -ef | grep metastore
5. kill <pid returned from previous step>
6. nohup hive --service metastore &
7. beeline -h jdbc:hive2://localhost:10000 -u hadoop
Now test your changes. Once you iterate and get the correct hive-site.xml settings, you can put them in your EMR config file and try launching a fresh cluster.
Friday, March 3, 2017
Tag-Based Security for EMR Clusters in a Shared AWS Environment
In an shared AWS environment with multiple developers, you often want to ensure developers have the ability to launch personal resources, and embed sensitive information into those resources, without the fear that sensitive information would be visible to your entire group of developers. Consider the following scenario:
Therefore the only modifications needed were
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "statement1",
"Condition": {
"StringEquals": {
"elasticmapreduce:RequestTag/owner": "${aws:username}"
}
},
"Effect": "Allow",
"Action": [
"iam:PassRole",
"iam:AddRoleToInstanceProfile"
],
"Resource": [
"arn:aws:iam::012345678910:role/EMR_DefaultRole",
"arn:aws:iam::012345678910:role/EMR_EC2_DefaultRole"
]
},
{
"Sid": "statement2",
"Condition": {
"StringNotEquals": {
"elasticmapreduce:ResourceTag/owner": "${aws:username}"
}
},
"Effect": "Deny",
"Action": [
"elasticmapreduce:AddTags",
"elasticmapreduce:Describe*"
],
"Resource": [
"*"
]
}
]
}
The key to tag-based authorization that was always missing from the picture in my mind was the RequestTag element and an IAM policy variable within a conditional allow statement. Statement 1 above effectively states that a developer is only allowed these elevated IAM privileges if he or she puts a tag on their resource request where tag name = owner and tag value = their username. This means they must put their username on every EMR resource request they make or the request will fail. Statement 2 above denies the developer the ability to add or remove tags, or to describe EMR resource unless the resource contains a tag where tag name = owner and tag value = their username.
- Developers want to launch personal resources for developing code
- Developers need to embed personal credentials for external services like databases into the services they launch, either by supplying EC2 user data at launch or via a resource config file like the EMR config file
- You do not want developers to see any resources or sensitive information other than their own
- You want an account admin to be able see all resources even if that admin is not an account owner
Therefore the only modifications needed were
- Allow users to add a limited set of IAM roles to EC2 instances
- Prevent users from seeing EMR service information for clusters they did not launch
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "statement1",
"Condition": {
"StringEquals": {
"elasticmapreduce:RequestTag/owner": "${aws:username}"
}
},
"Effect": "Allow",
"Action": [
"iam:PassRole",
"iam:AddRoleToInstanceProfile"
],
"Resource": [
"arn:aws:iam::012345678910:role/EMR_DefaultRole",
"arn:aws:iam::012345678910:role/EMR_EC2_DefaultRole"
]
},
{
"Sid": "statement2",
"Condition": {
"StringNotEquals": {
"elasticmapreduce:ResourceTag/owner": "${aws:username}"
}
},
"Effect": "Deny",
"Action": [
"elasticmapreduce:AddTags",
"elasticmapreduce:Describe*"
],
"Resource": [
"*"
]
}
]
}
The key to tag-based authorization that was always missing from the picture in my mind was the RequestTag element and an IAM policy variable within a conditional allow statement. Statement 1 above effectively states that a developer is only allowed these elevated IAM privileges if he or she puts a tag on their resource request where tag name = owner and tag value = their username. This means they must put their username on every EMR resource request they make or the request will fail. Statement 2 above denies the developer the ability to add or remove tags, or to describe EMR resource unless the resource contains a tag where tag name = owner and tag value = their username.
Sunday, October 5, 2014
Digging for Data: Unearthing the Locations of Farmers Markets in Boston - Part 1
There were five different files with two having the same name but different records, most having differing numbers of columns, and all having unique formats in the "Location" column, not to mention duplicate records here and there across files. Here are some snapshots of the files on the way in:
Farmers Markets w/Benefits

Summer Farmers Markets

Farmers Markets w/Fish

Farmers Markets w/Fish(1)

Winter Farmers Markets

In the end I wanted a single dataset with as much information as possible about each market. To achieve this, I turned to Alteryx. Here is what the first half of my data flow looked like in Alteryx.

You can see that after inputting each of the five text files involved, I used the Autofield tool to automatically convert as many fields as possible to the appropriate data type. Using the Text Input tool in conjunction with the Append Fields tool, I appended to both of the files representing farmers markets offering fish a new binary 'With Fish?' column to help differentiate them from the other markets later on. All of the files then underwent a parsing of some combination of the dates, times, and location fields.
I won't go into too much detail on parsing each and every field, but I will say the ability to embed RegEx into the Alteryx workflow proved invaluable here. If you need to parse on more than a single character or are interested in extracting specific bits of information from complex strings, RegEx is the only way to go.
Here is how the incoming Location column was structured in one of the files:

Here are the settings I entered into the RegEx tool:

And here are the columns I ended up with:

If you aren't already familiar with RegEx, I strongly recommend taking some time to learn it. I found this site particularly helpful when getting started (the only trick I used here that wasn't mentioned on that site was non-capturing groups).
Once every record across all files had a uniform address data structure, I used a series of joins, selects, and unions to remove any duplicate records. While Alteryx has the Unique tool, which lets you select what columns you consider keys and removes every record after the first that it finds with a specific key combination, I found that my approach allowed me to discard duplicates while being selective about which columns I kept around. When a duplicate was found, I took a combination of the most informative columns from each file and kept moving. You can see how my outer join was built in Alteryx below (the three duplicate patterns above one another). Two files are passed to the Join tool. Then all the records from the Left, Join, and Right outputs are unioned together using the Union tool. The Select tool in the middle removes any duplicate columns resulting from the successful Join.

After the final union we have our single record set. I then cleaned up a few fields all at once with the Multi-Field Formula tools, mostly to remove unnecessary spaces or convert null values in my Yes/No columns into 'Maybe's. Here's what my single file looked after the final Multi-Field Formula tool:

You'll notice there are more tools on the canvas and that we are still missing arguably the most important fields: latitude and longitude. That's because we have yet to discuss the Alteryx CASS tools.
The Alteryx CASS tools allow you to manipulate and augment address data in a variety of ways. With functions like address parsing, completion, and geocoding, the CASS tools compare input data to a file containing known addresses in the US and Canada. While you can only access these tools if you've purchased the Spatial package, and the Spatial package is a bit more pricey than the basic Designer package, it's pretty easy to appreciate the ROI if you work with addresses on a daily basis. I'll go over the specifics of these tools and how they fit into this data flow on my next post. For now just know that I would never have been able to finish incomplete addresses, correct inaccurate addresses, or assign accurate latitude and longitude coordinates for each market systematically without custom programming.
Just to recap I took five disparate files with different data structures, incomplete, and even inaccurate data, and blended them all together into a single source of cleanly addressed and geocoded truth using the workflow above. Before being introduced to Alteryx, I never would have thought that possible without involving a programming language like Python and a whole range of specialized libraries.
You can download all the files, both inputs and output, as well as the Alteryx module shown above using this link. Note that the module won't actually run to completion unless you have the appropriate data packages installed, but you should be able to run everything up to the CASS tools and at least see how the tools are configured with any edition of Alteryx.
Thanks for reading.
Sunday, September 28, 2014
Farmers Markets of Boston
Who doesn't love a good farmers market? Aside from the obvious benefits of access to freshly grown or recently homemade foods, I find the little details of the farmers market most rewarding. The dirt-stained hands and clothes of individuals who don't appear dirty all but rather more wholesome as a result of their profession. The early morning calm, the prideful eyes of vendors, and the curious hands and mouths of would-be buyers. Farmers markets somehow seem even more precious to those of us living in the twisted and tangled concrete jungles that are modern American cities.
To pay homage to all the street corners and public squares in Boston where slow, local food thrives, I've put together the map below. Find the closest market to you. Don't forget to check the dates and times of operation. Some markets are summer or winter only. Also it should be noted that the source of this information was a set of disparate government files from 2013 (the latest available). It was quite a feat to turn them into something useable, the process for which I plan to go over in my next post.
Enjoy.
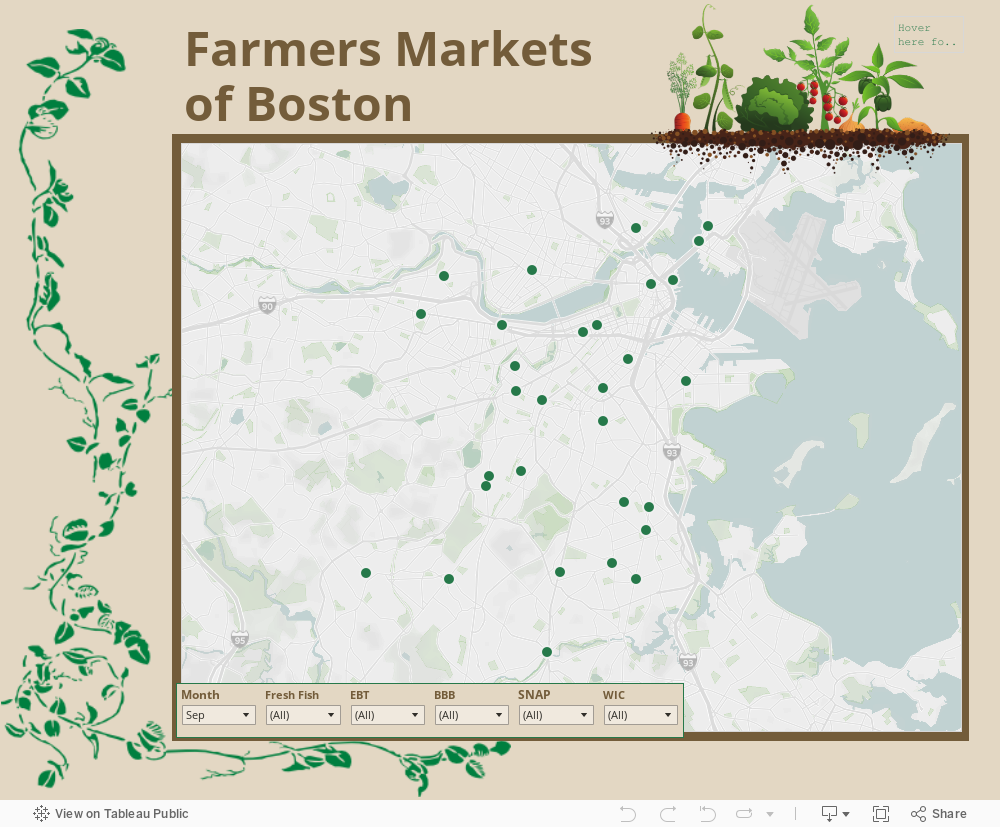
To pay homage to all the street corners and public squares in Boston where slow, local food thrives, I've put together the map below. Find the closest market to you. Don't forget to check the dates and times of operation. Some markets are summer or winter only. Also it should be noted that the source of this information was a set of disparate government files from 2013 (the latest available). It was quite a feat to turn them into something useable, the process for which I plan to go over in my next post.
Enjoy.
Wednesday, September 24, 2014
An Introduction to the Glut
As a relatively new convert to the field of data science, I find myself repeatedly and simultaneously excited, impressed, and humbled by the sheer volumes of data available to those willing to dig for it. The almost non-existent latency with which new information is gathered, stored, and disseminated globally is surely not a reality previous generations could have predicted.
Finding meaning in the veritable ever-accumulating glut of data that fills our lives, however, is no small feat. For that reason, I've chosen to chronicle my mining and munging, my scrubbing and scraping, in an attempt to share outcomes that I feel are either meaningful, interesting, or "cool." I hope and fully intend for my exposition of the process to be as intriguing as the outcomes themselves. After all, the more mundane the data set, the more extraordinary and creative of an approach required to transform that data into knowledge.
I plan to use a combination of relevant applications such as Alteryx and Tableau (both growing in popularity and power with each release) for data manipulation and visualization respectively. I fully expect Python and R to make their way into posts as well. I'm of the opinion that the future belongs to those who can both program software and perform statistical analysis. The days are numbered for statisticians incapable of implementing a MapReduce algorithm as well as for programmers able to write the algorithm but fall short when time comes to interpret the true value of the results. For that reason, I find that a combination of the tools above are almost limitless in their ability to acquire, crunch, and convey information: a proper data scientist's toolbox indeed.
Despite being at risk of becoming the often cited "jack of all trades, master of none," I find myself eager to test all the facets of being a modern data scientist before settling down into a deep trough of specific expertise. Hopefully you'll enjoy the escapades documented here as much as I do.
Subscribe to:
Comments (Atom)